
Zero-Downtime Deployments with Docker Compose
Some months ago, inspired by prior art, I cobbled together Docker Compose, Traefik, and some good old Bash scripting to implement a basic blue-green deployment process. It wasn't perfect, but it got the job done.
Recently I've been working on a new project and in the midst of migrating it to a virtual private server (VPS) dusted off this old implementation, making a few improvements along the way.
In this article we look more closely at how you might approach implementing zero-downtime deployments via blue-green deploys with Docker Compose.
Here's a git repo with an example of the complete implementation for reference.
Docker Compose
I've been having something of a love affair with Docker Compose recently. It's an ideal mix of functionality packaged up in minimal complexity that fits many of my projects well. It offers basic container orchestration, with some reasonable constraints, without dipping into the dark depths of tools like Kubernetes.
Moreover, it's incredibly easy to stand up on virtually any VPS. So long as there's a recent Docker installed, I can bring my Compose config with me and very quickly have a working environment. This approach makes the cost effectiveness of commodity hardware very accessible, with minimal impact to my own productivity.
However, where Kubernetes has robust and polished answers to virtually any production-grade workflow you might imagine, Compose may not. For instance, rolling updates will require you bringing your own answers.
Bring Your Own Deploy
Fortunately it's not too difficult to set up a fairly robust deployment process using modern tools like Traefik.
First let's take a moment to understand the dynamics of Docker in a little more detail so we can consider how we might approach a goal of zero-downtime. It's important to note that when a Docker container is updated it must be rebuilt and that the process of swapping out an old container for a new creates a gap in time during which no container is running. This is downtime and we want to avoid that.
A common way around this is to route traffic through some sort of reverse proxy network appliance. This could be NGINX or HAProxy, to name two popular options. Both are great and allow us to shape traffic independently of our container backend. In an architecture with a proxy, we can build a new container, stand it up in parallel with the old, and then start sending traffic to this new container before tearing down the old. This eliminates downtime.
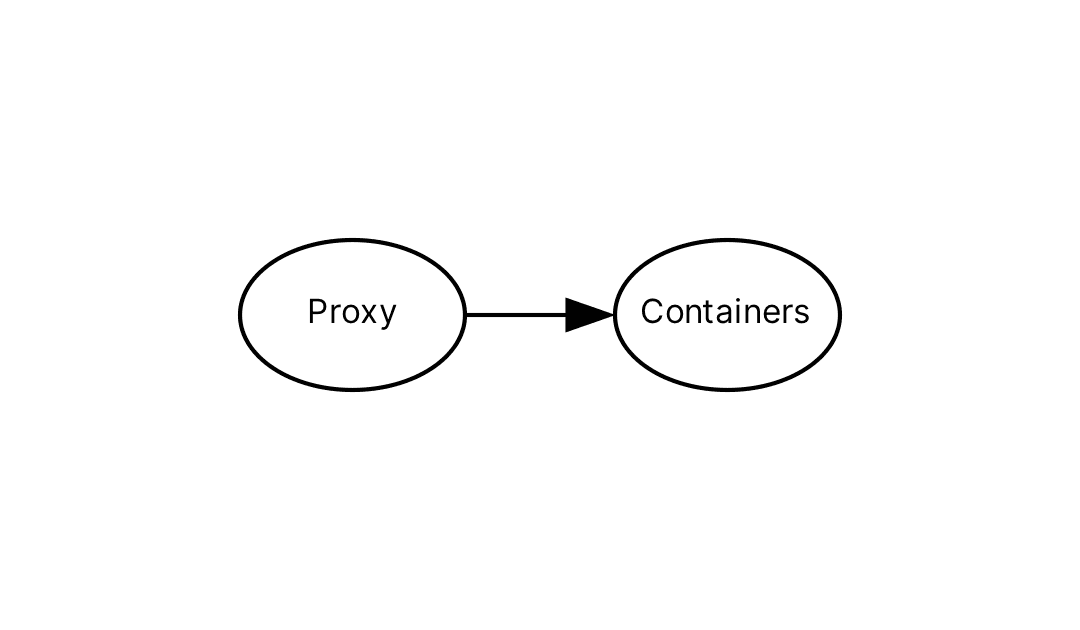
Both NGINX and HAProxy are excellent choices for such a task. However, neither is directly aware of Docker and require extra work as such. Instead we can consider newer tools, like Traefik via its Docker provider, which can streamline this process. Here we'll use Traefik where we'd otherwise use a different proxy, like NGINX.
Blue-Green Deploys
The blue-green deployment pattern works by standing up two environments: a blue environment and a green environment. Traffic will be routed to one of these environments at any given time and the process of rolling out new changes involves routing traffic to the inactive environment, usually after first updating that environment in some way. Should something go wrong, rolling back is as simple as pointing traffic back at the original environment. Once this is successfully completed, the inactive environment becomes the active environment and the process can begin anew.
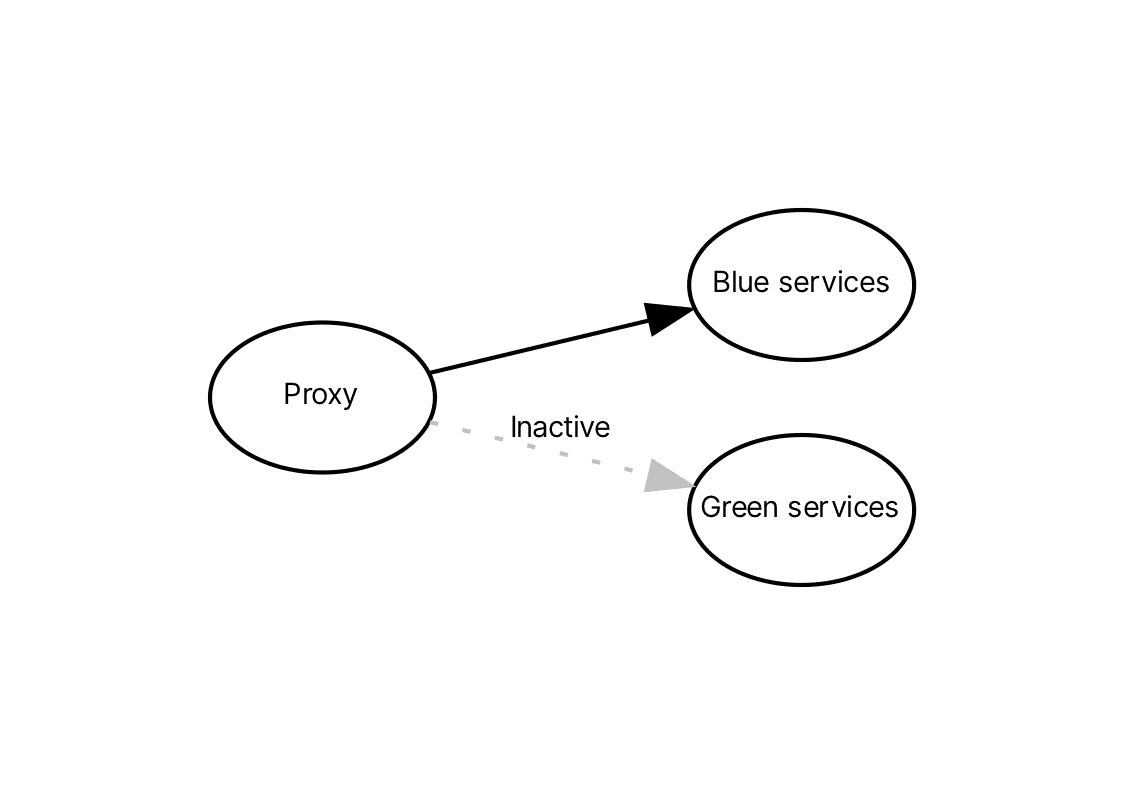
In our case we're going to combine Docker Compose, Traefik, and Bash to enable such a workflow. We'll define a blue and green service in our docker-compose.yml as well as a separate docker-compose.traefik.yml. Together these will house our blue-green environments and Traefik proxy respectively. We'll then operate deployments with a Bash script that will leverage the Docker command line interface as well as the Traefik API to update our environments while avoiding downtime.
Our Blue-Green Service
This is what our docker-compose.yml will look like:
version: "3"
services:
blue-web: &web
container_name: blue-web
build:
context: .
dockerfile: Dockerfile
labels:
- "traefik.enable=true"
- "traefik.http.routers.web.rule=PathPrefix(`/`)"
- "traefik.http.routers.web.entrypoints=web"
- "traefik.http.middlewares.test-retry.retry.attempts=5"
- "traefik.http.middlewares.test-retry.retry.initialinterval=200ms"
- "traefik.http.services.web.loadbalancer.server.port=3000"
- "traefik.http.services.web.loadbalancer.healthCheck.path=/health"
- "traefik.http.services.web.loadbalancer.healthCheck.interval=10s"
- "traefik.http.services.web.loadbalancer.healthCheck.timeout=1s"
restart: always
networks:
- traefik
green-web:
<<: *web
container_name: green-web
networks:
traefik:
name: traefik_webgateway
external: true
There's a few important things to note about this configuration:
-
We're using labels to configure Traefik dynamically. These labels tell Traefik how to interact with our service. In particular we've told Traefik that it should use the given path prefix and
webentry point (this will be configured in Traefik directly) when matching traffic to send to our service. -
We also specify a retry middleware. This is a very important feature of our implementation: without it, there can be downtime as Traefik may route to a service that's no longer available. This middleware ensures failed requests to the backend are retried via the specified parameters.
-
Then we tell the Traefik load balancer how to connect to our server running in the container and provide it with a health check. This health check is also important as it allows Traefik to add and remove containers from the active pool it will route to.
-
Another important detail here is our network definition. Both Traefik and our services will run within this network. By putting Traefik and our services on the same network, Traefik can work directly with Docker to discover our services in a native fashion.
Our Traefik Proxy
Moving on to Traefik itself, this is what our docker-compose.traefik.yml will look like:
version: "3"
services:
traefik:
container_name: traefik
image: traefik:v2.9
labels:
- "traefik.http.routers.api.rule=Host(`localhost`)"
- "traefik.http.routers.api.service=api@internal"
networks:
- webgateway
ports:
- "80:80"
- "127.0.0.1:8080:8080"
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- ./traefik.yml:/traefik.yml
restart: unless-stopped
networks:
webgateway:
driver: bridge
Let's take a closer look:
-
We ensure that we've mapped a port,
:80, we can route public traffic to. Later we'll define an entry point for this in ourtraefik.yml. We've also mapped a local binding to the Traefik dashboard on:8080; we do not want to expose this publicly. -
Volume definitions map the Docker socket and our
traefik.ymlbelow into the Traefik container. The Docker socket is leveraged by Traefik for container access and the configuration provides some important details about how Traefik will be run. -
Here we're establishing our shared network
webgatewaynetwork, the same network our services reference in order to be available to Traefik directly.
Our traefik.yml configuration looks like this:
log:
level: INFO
accessLog: {}
api:
dashboard: true
insecure: true
entryPoints:
web:
address: ":80"
providers:
docker:
endpoint: "unix:///var/run/docker.sock"
exposedByDefault: false
watch: true
network: traefik_webgateway
Lastly our traefik.yml configures:
-
The API (we'll use this later to ensure our containers are successfully registered with Traefik) and internal dashboard,
-
An entry point for public traffic, bound to port
80; clients can connect directly to this or we could place another intermediary between Traefik and the public Internet, -
And a Docker provider, which uses the socket we've mapped as a volume as well as the
traefik_webgatewaynetwork we've previously configured.
Assembly
We've partitioned Traefik and our services configuration because we want to operate Traefik independently of the rest of our system.1 As such, we'll run Traefik on its own like so:
docker compose --project-name=traefik --file docker-compose.traefik.yml up --detach
With this running, we can now run our services and begin routing traffic to them via Traefik. Here we're going to such a bit of Bash scripting. This script will make use of the Docker command line as well as the Traefik API. Its goal is to implement the blue-green strategy by identifying which service, blue or green, is currently active and then standing up the inactive environment in parallel. Bear in mind we want to avoid downtime and so the script will use Docker and Traefik to ensure the new service is both healthful and recognized by Traefik before it shuts down the old service.
#!/bin/bash
set -euo pipefail # Enable strict mode
BLUE_SERVICE="blue-web"
GREEN_SERVICE="green-web"
SERVICE_PORT=3000
TIMEOUT=60 # Timeout in seconds
SLEEP_INTERVAL=5 # Time to sleep between retries in seconds
MAX_RETRIES=$((TIMEOUT / SLEEP_INTERVAL))
TRAEFIK_NETWORK="traefik_webgateway"
TRAEFIK_API_URL="http://localhost:8080/api/http/services"
# Find which service is currently active
if docker ps --format "{{.Names}}" | grep -q "$BLUE_SERVICE"; then
ACTIVE_SERVICE=$BLUE_SERVICE
INACTIVE_SERVICE=$GREEN_SERVICE
elif docker ps --format "{{.Names}}" | grep -q "$GREEN_SERVICE"; then
ACTIVE_SERVICE=$GREEN_SERVICE
INACTIVE_SERVICE=$BLUE_SERVICE
else
ACTIVE_SERVICE=""
INACTIVE_SERVICE=$BLUE_SERVICE
fi
# Start the new environment
echo "Starting $INACTIVE_SERVICE container"
docker compose up --build --remove-orphans --detach $INACTIVE_SERVICE
# Wait for the new environment to become healthy
echo "Waiting for $INACTIVE_SERVICE to become healthy..."
for ((i=1; i<=$MAX_RETRIES; i++)); do
CONTAINER_IP=$(docker inspect --format='{{range $key, $value := .NetworkSettings.Networks}}{{if eq $key "'"$TRAEFIK_NETWORK"'"}}{{$value.IPAddress}}{{end}}{{end}}' "$INACTIVE_SERVICE" || true)
if [[ -z "$CONTAINER_IP" ]]; then
# The docker inspect command failed, so sleep for a bit and retry
sleep "$SLEEP_INTERVAL"
continue
fi
HEALTH_CHECK_URL="http://$CONTAINER_IP:$SERVICE_PORT/health"
# N.B.: We use docker to execute curl because on macOS we are unable to directly access the docker-managed Traefik network.
if docker run --net $TRAEFIK_NETWORK --rm curlimages/curl:8.00.1 --fail --silent "$HEALTH_CHECK_URL" >/dev/null; then
echo "$INACTIVE_SERVICE is healthy"
break
fi
sleep "$SLEEP_INTERVAL"
done
# If the new environment is not healthy within the timeout, stop it and exit with an error
if ! docker run --net $TRAEFIK_NETWORK --rm curlimages/curl:8.00.1 --fail --silent "$HEALTH_CHECK_URL" >/dev/null; then
echo "$INACTIVE_SERVICE did not become healthy within $TIMEOUT seconds"
docker compose stop --timeout=30 $INACTIVE_SERVICE
exit 1
fi
# Check that Traefik recognizes the new container
echo "Checking if Traefik recognizes $INACTIVE_SERVICE..."
for ((i=1; i<=$MAX_RETRIES; i++)); do
# N.B.: Because Traefik's port is mapped, we don't need to use the same trick as above for this to work on macOS.
TRAEFIK_SERVER_STATUS=$(curl --fail --silent "$TRAEFIK_API_URL" | jq --arg container_ip "http://$CONTAINER_IP:$SERVICE_PORT" '.[] | select(.type == "loadbalancer") | select(.serverStatus[$container_ip] == "UP") | .serverStatus[$container_ip]')
if [[ -n "$TRAEFIK_SERVER_STATUS" ]]; then
echo "Traefik recognizes $INACTIVE_SERVICE as healthy"
break
fi
sleep "$SLEEP_INTERVAL"
done
# If Traefik does not recognize the new container within the timeout, stop it and exit with an error
if [[ -z "$TRAEFIK_SERVER_STATUS" ]]; then
echo "Traefik did not recognize $INACTIVE_SERVICE within $TIMEOUT seconds"
docker compose stop --timeout=30 $INACTIVE_SERVICE
exit 1
fi
# Set Traefik priority label to 0 on the old service and stop the old environment if it was previously running
if [[ -n "$ACTIVE_SERVICE" ]]; then
echo "Stopping $ACTIVE_SERVICE container"
docker compose stop --timeout=30 $ACTIVE_SERVICE
fi
Let's step through the script piece by piece:
-
First we make some assumptions about the names of our services (previously defined in our Docker Compose configuration) and the port our service is running on, as well as the network, and Traefik API host name.
-
We then use Docker directly to see which environment, if any, is active. If none is active, we specify as such and set blue as inactive (since this is the environment we'll stand up first).
-
In our script we're going to combine the action of building the container, but this could instead pull a built image, either way we'll begin by standing up the inactive service.
-
Once we do, we need to wait for this service to become healthful.2 We'll loop for a specified amount of time (60 seconds) waiting to find the container IP. Once we find the IP we then check the health endpoint, looking for a successful response.
- If we timeout during this process then the deploy fails. In such a case, we stop the inactive container and exit with a non-zero exit code.
-
Once we've passed the first health check, we look to see that Traefik also recognizes the inactive container. Similarly, we'll reuse our timeout here, waiting to see positively the container has been registered and has an
"UP"status.- Likewise if this times out then we'll stop the inactive container and exit with a non-zero exit code.
-
Finally, if there was an active service when we began, we'll stop that service to ensure Traefik does not route new traffic to it.3 We've now completed the entire workflow.
To author a new deploy, we'll run this script: $ ./blue-green-environment.sh. As mentioned above, it'll also take care of building our container image, but depending on our setup, we might opt to have it pull from a registry instead. We could also consider automating this process by running this script based on some trigger, such as a commit to our main branch.
Zero-Downtime Deploys
With a reverse proxy and some scripting, we can lean on the power of tools like Docker to create a reasonably simple system for safely deploying new versions of our services without causing downtime in the process.
One advantage to our particular approach is the fact that we do not map ports from our containers. This isn't necessary for Traefik, given it's operating in the same network as our container backend. Furthermore, this allows us to stand up any number of backend services, without needing to directly manage their port bindings. This quite nice for scalability and has been historically difficult to achieve, with prior art requiring e.g. extensive scripting over .e.g NGINX or static port mapping.4
It's worth pointing out that our implementation, like all real world implementations, is not perfect. We rely on the retry middleware to ensure that Traefik doesn't fail when a container we're spinning down receives a request – more ideally, we might like to proactively remove this container from Traefik's pool before shutting it down.5 We will also route traffic to both environments during this process, so this should be taken into account when considering how our application will be updated.
However, depending on your use case, this may well be plenty good enough. In the case of RemoteJobs.org, it's more than what we need.6
If you'd like to poke around something more concrete or have suggestions for ways of improving this implementation, I've put together a git repo which I welcome folks to take a closer look at.
Footnotes
-
Routing traffic needn't be tied to the other parts of our system and decoupling these two concerns is a robust and resilient pattern. ↩
-
In this example, we're simply looking for any successful response. However, we could configure a more sophisticated introspection of the response. ↩
-
There is a potential gap in our implementation here: Traefik does not currently support connection draining and so our backend application needs to take this into consideration. ↩
-
The nginx-proxy project is a mature example of this approach. ↩
-
To go further with this, we might have to leverage the File Provider, instead of the Docker provider. This is more complex approach and out of the scope of this article. ↩
-
You could say it's over-engineered, however, this same script is used across multiple projects, some of which have far less tolerance for downtime. ↩
A Newsletter to Share My Knowledge
I built this site to share everything I know about leadership, building startups, and indie hacking. This newsletter is another way for me to provide that value to you.
What you get for signing up:
- Exclusive content tailored just for our newsletter
- Notifications when I add new content
- Occasional access to unpublished and draft work
All signal, no noise. Unsubscribe at any point.